Importer nos données
Comment faire de l'analyse de données sans données ? Les données sont la matière première du chercheur ou du data scientiste. Avant de faire quoi que ce soit, il nous faut obtenir des données. Nous allons voir dans ce chapitre les principaux formats de données existant, et comment travailler avec pour les transformer en dataframe que nous pourrons manipuler.
Il existe de nombreux formats de données. Ici nous allons présenter uniquement les deux principaux, à savoir les fichiers .csv et les fichiers excels. Si jamais vous avez besoin de travailler avec un format de données différents, n'hésitez pas à chercher de l'aide dans la documentation du package readr !
le package readr
Le package que nous allons utiliser pour la lecture de nos données est readr , qui fait parti du tidyverse. R comporte déjà de base de nombreuses fonctions pour importer des données, mais elles ont des petits défauts et limitations qui font que readr est plus apprécié. C'est pourquoi au lieu de vous apprendre les fonctions de bases et de vous voir confronter a leurs limites plus tard, nous avons choisit de directement vous apprendre à utiliser readr. Quand cela sera possible, nous vous expliquerons en quoi la fonction apportée par readr est plus pertinente que la fonction existante dans R.
Normalement, si vous avez installé le tidyvserse au chapitre précédent, readr est déjà installé. Si ce n'est pas le cas, vous pouvez l'installer maintenant, puis le charger.
install.packages("readr")
library("readr")
Nous n'allons ici voir que les principales fonctions du package. N'hésitez jamais à consulter la documentation en ligne pour découvrir les autres fonctions et les différents paramètres de chacune d'elle ! De plus, il existe une "feuille d'aide" qui regroupe les principales fonctions du package ! Pratique à avoir sous la main quand on cherche rapidement une information.
Le format csv
La plupart des fichiers de données sont au format .csv , qui signifie "Comma-separated values". Quand vous récupérer des données d'institutions académiques, la majorité vous proposeront de télécharger vos données en .csv . Voici par exemple un screen du site de la banque mondiale :
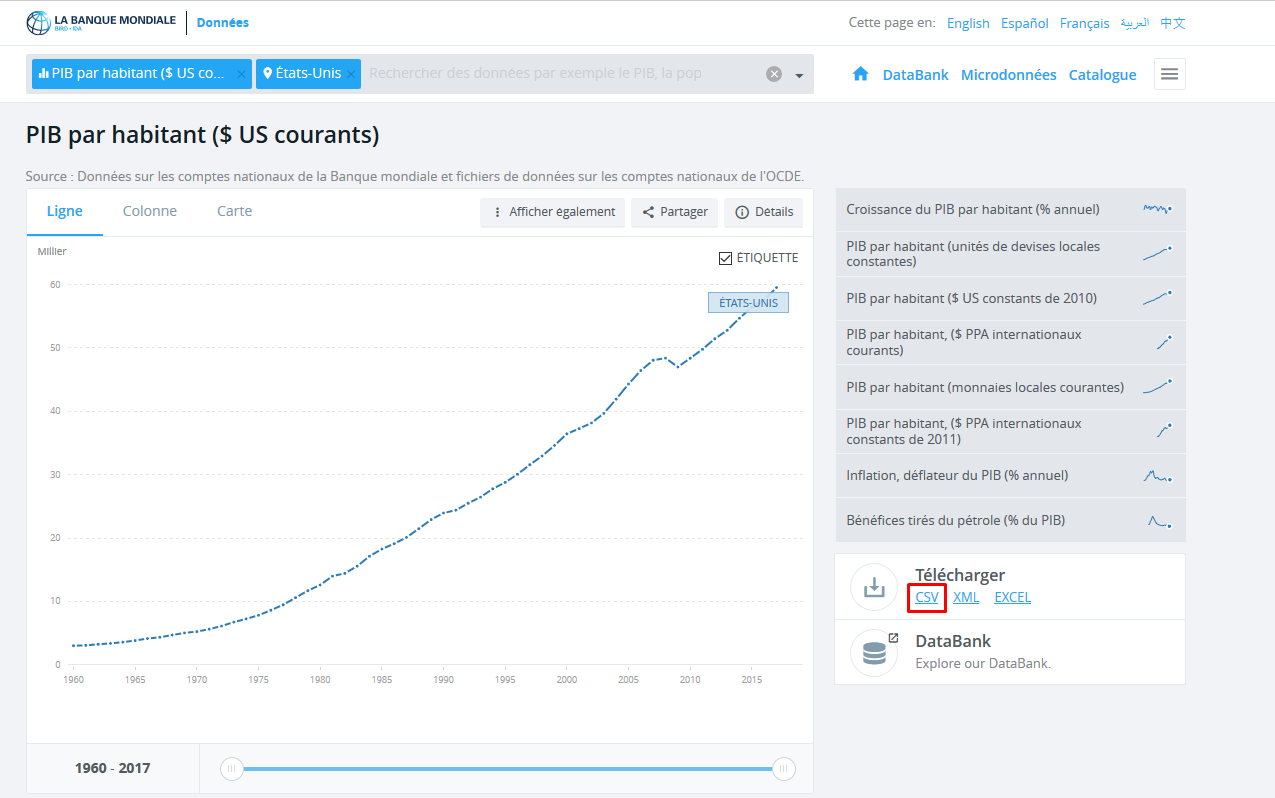
On peut voir que le site propose un lien pour télécharger directement les données qui nous intéressent au format .csv . Ici, nous avons selectionné le PIB par habitant pour les Etats-Unis entre 1960 et 2017.
Il est important de comprendre comment un fichier .csv est organisé, et comment le lire en R.
La structure d'un format .csv
Un fichier csv est en réalité un simple fichier texte dans lequel les différents éléments sont séparés par une virgule. Voici les données qui représentent la population de la Belgique, de la France et de l'Allemagne en 1992, 1997 et 2002 :
Belgium, 10045622, 10199787, 10311970
France, 57374179, 58623428, 59925035
Germany, 80597764, 82011073, 82350671
On peut voir que chaque élément est séparé des autres via une virgule, et que il suffit de sauter une ligne pour passer à la ligne suivante. La structure d'un fichier .csv est très simple, ce qui la rend facile à utiliser et à modifier directement.
Le header et le délimiteur
Il arrive que la première ligne d'un fichier .csv indique les noms des différentes variables. On dit que cette ligne est le header (en tête) du fichier. Notre exemple avec un header ressemblerait à ceci :
country, 1992, 1997, 2002
Belgium, 10045622, 10199787, 10311970
France, 57374179, 58623428, 59925035
Germany, 80597764, 82011073, 82350671
Notre header correspond à la premiére ligne :
country, 1992, 1997, 2002
Le header est très utile, car il nous permet de connaitre les titres de différentes colonnes de notre base de données. Si le fichier de contient pas de header, nous devrons nous-même trouver à quoi correspond chaque colonne. Il est important de savoir si votre fichier comporte un header un nom, pour indiquer à R d'en tenir compte.
Le délimiteur
Le nom du format .csv indique que les valeurs sont séparées par des , . Mais ce n'est pas toujours le cas. Parfois le délimiteur est plutôt des points virgules ; , voir un espace vide . Dans ce cas là, il faudrait là aussi indiquer cette particularité à R pour que votre fichier soit pris en compte correctement.
Ce format .csv qui utilise les ; au lieu des , est courant dans les données françaises ou européennes. Par exemple, si on cherche l'historique de l'inflation de l'insee (disponible ici), on obtient un fichier .csv dont les éléments sont séparés entre eux par des points-virgules.
Remarque : En pratique, tous les fournisseurs de données ne respectent pas toujours exactement la structure que nous vennons de décrire. Cela signifie qu'il est parfois possible que votre fichier commence par des lignes vides (et non par un header ou une ligne normale), ou des lignes suplémentaires.
Lors ce que vous travaillerez pour la première fois avec des fichiers .csv venant de sources extérieur, ne paniquez pas si vous avez des difficultés à charger votre fichier. Pensez à bien en regarder la structure. Par exemple, les fichers .csv recupérés sur les sites de la banque mondiale ou de l'insee sont rarement utilisables en l'état !
Construire notre propre ficher .csv
Construisons notre propre ficher de données au format .csv . Cela nous permettra non seulement de mieux nous familliariser avec ce format, mais aussi d'éviter de travailler avec une base de données réelle trop complexe ou mal formatée. Pour cela, faites un clic droit à l'endroit où vous voulez créer le ficher, puis "nouveau" > "document texte". Appelons ce document "data".

Notre document est pour le moment un document texte, et non un document .csv . Ouvrons le en double-cliquant dessus, puis faisons "fichier" > "enregistrer sous" et enfin renommons le data.csv :

Une fois le fichier enregistré, il devrait apparaitre dans votre dossier. Ici, comme Excel est configuré pour reconnaitre et ouvrir les fichiers .csv , l'icone de notre fichier est une icone de feuille Excel. Mais on voit bien que le format du fichier est de type csv : Notre précédent document texte
Notre précédent document texte data est toujours présent, nous pouvons le supprimer. Maintenant, ouvrons notre fichier data.csv . Nous voulons l'ouvrir avec le bloc note, via "clic-droit" > "ouvrir avec" > "bloc-notes".

Notre fichier .csv vide s'ouvre alors ! Il est vide pour le moment :
Nous allons copier-coller dans le fichier les données d'exemple données précédement, avec le header :
country, 1992, 1997, 2002
Belgium, 10045622, 10199787, 10311970
France, 57374179, 58623428, 59925035
Germany, 80597764, 82011073, 82350671
Vous pouvez aussi recopier manuellement le contenu, en sépérant chaque élément par une virgule et en sautant une ligne quand cela est nécessaire. Une fois le fichier recopié, vous pouvez l'enregistrer. Nous avons créer notre premier fichier .csv . Comme ce fichier est simple, nous pourrons le modifier facilement pour tester différents paramètres. Par exemple voir ce qui se passe si on enlève le header, ou si on remplace les , par des ; .
Lire un fichier .csv
Maintenant que nous avons notre fichier de données data.csv , nous pouvons enfin apprendre à le lire et à importer ces données dans R.
Le package readr fournit trois fonctions de base pour lire les fichiers .csv . la fonction read_csv() , qui permet de lire les fichiers .csv "classiques". La fonction read_csv2() qui lit les fichiers .csv délimités par un point virgule (et non une virgule). Et enfin la fonction read_tsv() qui lit les fichiers où la virgule est remplacée par un espace .
Ces trois fonctions ont exactement la même syntaxe, ce qui fait qu'une fois que vous comprennez le fonctionnement d'une, vous pouvez aussi utiliser les autres. La différence consiste simplement à utiliser la bonne fonction pour le bon type de fichier, ce qui demande de connaitre la structure de votre fichier .csv avant de tenter de l'importer dans R.
Ici, nous allons présenter uniquement la fonction read_csv() , car notre fichier d'exemple data.csv est un fichier .csv tout ce qu'il y a de plus classique.
Pour lire un fichier avec cette fonction, il suffit de lui passer en premier argument file le chemin vers le fichier à charger.
data = read_csv(file = "data.csv")
data = read_csv("data.csv") #On peut ne pas écrire le nom de l'argument
Ici, on charge le fichier data.csv qui se trouve dans le même dossier que notre dossier de travail. Si vous ne vous souvenez plus comment choisir votre dossier de travail, relisez le premier chapitre de la partie précédente du livre.
Vous devriez alors obtenir une nouvelle variable dans votre environnement :

De façon surprenante, cette variable n'est pas d'une classe connue (souvenons nous que l'environnement affiche la classe d'un objet bien que la colonne en question s'appelle type). En réalité, les fonctions de readr nous retournent des tibble , qui sont des data.frame un peu particulier. Nous y reviendrons juste après !
Si on double clique sur notre variable data depuis l'environnement, elle va s'ouvrir exactement comme quand on affiche un data.frame :
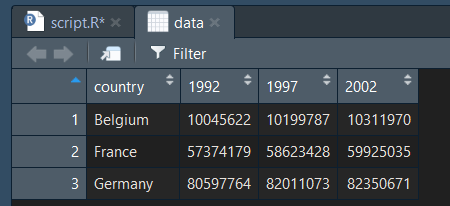
Comme on peut le voir, la fonction read_csv() a directement reconnu le header, et à nommée les colonnes de la bonne façon. De plus, si on regarde la console, un affichage est apparu :

Ces lignes nous indiquent que la fonction à directement reconnu le type de chaque colonne de notre dataframe, et nous en affiche le type. Ainsi la variable country est bien de type character , et les trois autres variables 1992 , 1997 et 1999 correspondent aux populations des pays, et sont donc de type double .
Une couleur est associée à chaque type de variable, pour rendre la lecture plus rapide : rouge pour les chaines, vertpour les nombres, et orange pour les booléans. Cela est très pratique, par exemple pour voir si une colonne à été mal interprétée par la fonction d'importation.
Les principaux paramétres de la fonction read_csv()
Nous allons voir maintenant les principaux paramètres de la fonction read_csv() (qui sont les mêmes que ceux de read_csv2() et de read_tsv() ). N'hésitez pas à consulter la documentation pour connaitre plus de détails sur ces paramètres ainsi que découvrir les autres paramètres que nous ne présentons pas ici.
Personnaliser ou supprimer le header
La fonction read_csv() considère par défaut que notre fichier .csv dispose d'un header. Il arrive parfois que cela ne soit pas le cas. On peut alors l'indiquer en utilisant le paramètre col_names() que l'on peut mettre à FALSE .
data = read_csv("data.csv", col_names = FALSE) #On lit un fichier sans header
Dans ce cas là, R va nommer automatiquement les colonne, de la façon suivante : X1, X2, X3, etc.

Vous pouvez aussi utiliser ce paramètre pour passer un vecteurs de chaines de caractères, afin de renommer les colonnes du data frame qui sera créer. C'est souvent nécessaire, que ça soit par ce que votre fichier .csv ne contient pas de header, ou par ce que les noms qu'il donne aux colonnes ne sont pas très bien choisis.
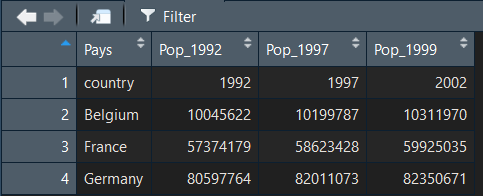
Les noms des colonnes de notre header sont en anglais. Profitons de l'importation pour les renommer !
names = c("Pays", "Pop_1992", "Pop_1997", "Pop_1999")
data = read_csv("data.csv", col_names = names)
View(data)
Nos colonnes ont bien été renommées :
Modifier le type de certaines colonnes
Comme nous l'avons vu, la fonction read_csv() va automatiquement essayer de detecter le type de chaque colonne, pour la convertir dans le vecteur correspondant. Néanmoins, il arrive parfois que la fonction n'arrive pas à deviner le type correctement. Par exemple, il est courant de représenter des variables booléans par des 0 et des 1 , alors que read_csv() ne reconnaitra comme booléans que des TRUE ou FALSE .
Ajoutons une colonne à notre data frame (en l'éditant via le bloc note) pour voir ce qui se passe :
country, 1992, 1997, 2002, FrenchSpeacking
Belgium, 10045622, 10199787, 10311970, 1
France, 57374179, 58623428, 59925035, 1
Germany, 80597764, 82011073, 82350671, 0
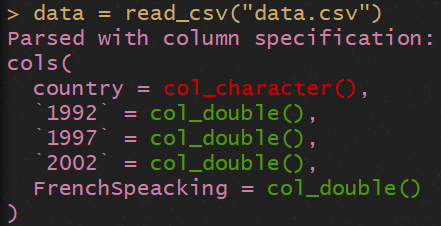
Cette colonne FrenchSpeacking contient une variable qui vaut 0 si le pays en question ne parle Français, et 1 si il est francophone. Importons alors nos données :
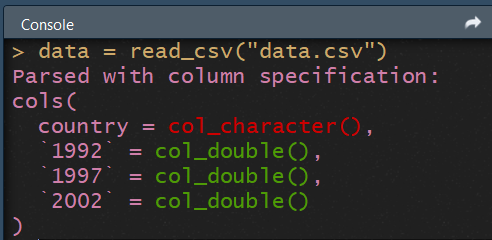
data = read_csv("data.csv")
Comme on peut le voir dans la console, la colone FrenchSpeaking est interprétée comme des nombres ("FrenchSpeacking = col_double()"), et non comme des booléans !
Il est heureusement possible de modifier les types des différentes colonnes, à l'aide du paramètre col_types . Ce paramètre accepte un objet de classe col_spec , qui est facile à construire. Il suffit d'utiliser la fonction cols()et de préciser les noms de chaque colonne, avec les fonctions de conversions associées.
Ici, spécifions le type de la colonne FrenchSpeacking , avec la fonction col_logical(), comme ceci :
colonnes = cols(FrenchSpeacking = col_logical())
data = read_csv("data.csv", col_types = colonnes)
On créer en premier un objet col_spec avec la fonction colonne, en précisant le nom des colonnes dont on veut modifier le type. Ici, on modifie FrenchSpeacking pour en faire un logical. Pour toutes les autres colonnes qui ne sont explicitement nommées, R va simplement deviner leur type comme à son habitude.
On passe alors cette variable colonne en paramétre col_types lors de l'importation. On peut voir que notre colonne FrenchSpeacking est différente, et affiche bien des booléans :
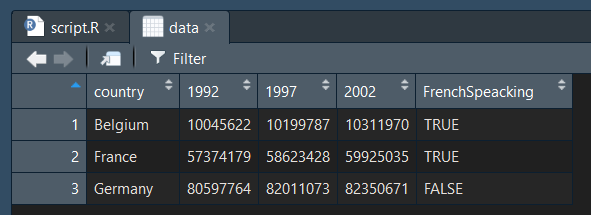
On peut le vérifier facilement :

L'objet col_spec :
Nous avons déjà rencontré la fonction cols() lorsque nous importons des données ! C'est exactement que qu'affiche la console pour nous dire le résultat des "devinettes" de R sur le type de nos colonnes :
R procéde en réalité de la façon suivante lors de l'importation des données :
- Il essaye de deviner le type de chaque colonne via une fonction spéciale. Pour cela il se base sur les 1000 premières lignes de chaque colonne.
- Il associe alors un type à chaque colonne, à l'aide de la fonction
cols()et des fonctions de conversion associées à chaque type (commecol_logicial()). - Il passe l'objet de classe
col_specretourné par la fonctioncols()en paramètre à la fonctionread_csv().
Si on ne précise pas nous même de types pour certaines variables pour la fonction cols() , alors tous les types seront revinés automatiquement par R. Pour éviter cela, nous pouvons construire nous même l'objet col_type à l'aide de la fonction cols() et passer en paramétre les noms des variables qui posent probléme et leur type associé.
Il existe différents fonctions a paser en paramètre à cols() chacune adaptée à un différent type :
col_logical()que vous avons déjà rencontré, qui indique la colonne devrait être convertie en bolean.col_integer()pour les entiersinteger.col_double()pour lesdouble.col_character()pour les chaines de caractères.col_skip()pour ne pas importer cette colonne.col_guess()pour deviner le type. C'est ce qui est utilisé par défaut.
Il existe aussi trois fonctions pour les dates :
col_date(format == "")pour les dates.col_time(format = "")pour les heures/minutes/secondes.col_datatime(format = "")pour les objets datatime (date + heure/minutes/secondes).
Formes raccourcis :
Il existe une forme raccouri pour les types de base, c'est à dire les fonctions que l'on passe à cols()sans paramètre (comme col_logical() par exemple). On peut remplacer chaque fonction par la première lettre du type associé :
"l"pour leslogical."i"pour lesinteger."d"pour lesdouble."c"pour lescharacter.
En utilisant cette forme raccourçie, notre exemple devient :
data = read_csv("data.csv", col_types = cols(FrenchSpeacking = "l"))
Si vous n'avez pas besoin d'importer de dates, nous vous conseillez donc d'utiliser les formats racourcis, bien plus pratiques.
Gérer les données manquantes
En R, les données manquantes sont représentées par le type NA . Par défaut, la fonction read_csv() reconnait les valeurs NA et les espaces vides ` comme des valeurs manquantes. Il est néanmoins possible de lui dire de considérée d'autres éléments comme des valeurs manquantes, via le paramétrena` de la fonction :
data = read_csv("data.csv", na = c("", "NA", "0"))
Ici, on indique que les valeurs 0 seront aussi considées comme des valeurs manquantes, et remplacées par des NA .
Le paramètre quoted_na permet lui de dire si les valeurs manquantes entre guillement "NA" doivent être traités comme des chaines ou comme des valeurs manquantes. Par défaut, quoted_na = TRUE , ce qui veut dire que les "NA" sont considérés comme des NA et non comme des chaines.
data = read_csv("data.csv", quoted_na = FALSE)
Enfin, on peut décider de totalement ignorer ou non les lignes vides, avec le paramètre skip_empty_rows . Par défaut, ce paramètre est à TRUE ce qui veut dire que les lignes vides sont simplement oubliées. Si on passe le paramètre à FALSE , les lignes vident seront représentées avec des NA pour chaque valeur.
data = read_csv("data.csv", skip_empty_rows = FALSE)
Sauter des lignes vides en début de document
Il arrive souvent que les fichiers .csv commencent par une série de lignes vides ou d'explication. C'est par exemple le cas de certains fichiers de données de la banque mondiale. Si on essaye de lire directement le fichier depuis le début, cela provoquera une erreur. Il est utile de pouvoir dire à R de sauter des lignes avant de commencer. Pour cela, on utilise le paramètre skip .
data = read_csv("data.csv", skip = 4) #On saute les 4 premières lignes
Nombre de lignes et progrès
On peut choisir le nombre de lignes qui vont être lu dans le fichier avec le paramètre n_max . Cela peut être utile si votre fichier est très long et que vous ne voulez que certaines lignes.
data = read_csv("data.csv", n_max = 1000) #on lit seulement les 1000 premiéres lignes
Si votre ficher est très long, vous pouriez trouvez utile de savoir à quel rythme avance la lecture. Pour cela, vous pouvez utiliser le paramètre progress et le mettre à TRUE . Par défaut, il est desactivé. Cela n'est néanmoins utile pour de gros fichiers, avec au moins un million de lignes ! La barre de progression sera mise à jour environ tous les 50 000 lignes.
data = read_csv("data.csv", progress = TRUE) #on veut charger un très gros fichier !
Nous avons vu les principaux paramètres des fonctions de lecture des fichiers csv . Vous devriez être capable d'importer n'importe quel fichier de ce type maintenant et de le transformer en dataframe prêt à être manipulé !
Read_csv() vs read.csv()
Il existe de base en R une fonction read.csv() pour lire les fichiers .csv . Nous allons expliquer ici les avantages des fonctions du package readr sur la fonction de base. Il existe plusieurs différences entre ces fonctions :
- Les fonctions de
readrsont beaucoup plus rapide. Au moins 10 fois plus rapides. Si vous devez lire des fichiers volumineux, la différence sera flagrante. - La fonction
read.csv()n'est pas très bonne pour reconnaitres les types des variables. Par défaut, elle considère toutes les chaines de caractères comme des facteurs ! - Les fonctions de
readrproposent une barre de progression, ce queread.csv()ne propose pas. - Il existe quelques autres petits avantages pour
readrque nous ne mentionnerons pas ici mais que vous pourrez trouver dans la documentation.
Pour toutes ces raisons, il est préférable d'apprendre directement à utiliser les fonctions de lecture du tidyverse , plutôt que de travailler avec les fonctions de base, qui se révelerons un jour être plus limitées et moins efficaces.
Lire un fichier excel
Il est possible que vous ayez parfois à travailler avec des données venant d'un fichier excel. Il est alors possible de soit convertir ce fichier au format csv, soit d'importer le fichier excel directement. Voici par exemple notre ficher d'exemple sous forme de tableau excel :
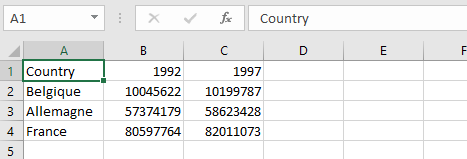
Pour pouvoir lire ce document, nous allons avoir besoin d'un nouveau package : readxl . Il est déjà inclut dans le tidyverse, donc nous n'avons pas besoin de l'installer. Nous devons néanmoins le charger manuellement car ce n'est pas un package de base.
library("readxl")
On peut ensuite lire notre fichier avec le fonction read_excel :
data2 = read_excel("data2.xlsx")
N'hésitez pas consulter la documentation pour voir les différents paramètres de la fonction. En particulier, vous pouvez lire uniquement certaines plages de cellules ou certaines colonnes/lignes avec le paramètre range .
A retenir
- La plupart des fichiers de données sont au format
.csv, qui signifie que les différentes valeurs sont séparées par des virgules. - Certains fichiers
.csvutilisent un;au lieu de la,et disposent d'un header. Le header est la première ligne du fichier, qui indique les noms des colonnes. - Certains institutions fournissent des fichiers
.csvmal formatés, avec des lignes en trop par exemple. Il est important de bien connaitre la structure de votre fichier avant de tenter de l'importer. - Le package
readrcomporte trois fonctions similaires pour lire les fichiers.csv:read_csv(),read_csv2()etread_tsv()qui lisent respectivement les fichiers dont le séparateur est une,, un;ou un - Ces fonctions prennent en premier paramètre un chemin vers un fichier
.csvet l'importent sous forme d'un tibble (qui sont des dataframe dont nous parlerons au chapitre suivant). - Vous pouvez choisir de ne pas lire le header (par défaut les fonctions prennent la première ligne pour le header), renommer les colonnes, ou encore ne lire qu'un nombre limité de lignes grace aux paramètre de la fonction
read_csv(). - Vous pouvez lire des tableaux excels à l'aide du package
readxlet de sa fonctionread_excel().