3.7 Les tableaux de données
Dans ce chapitre, nous allons voir l'une des structure de données les plus importante et les plus utilisée en R : les tableaux de données, ou plus souvent appelés par leur nom anglais data frames. C'est la structure la plus courante pour représenter des données à traiter. Nous employerons alternativement les deux dénominations de façon indifférente tout au long de ce cours.
Un data frame, c'est quoi ?
Un data frame est une structure de données qui nous permet de représenter des données de différentes natures ensemble. Il offre ainsi plus de flexibilité que les matrices qui ne peuvent contenir que des données de même type.
Supposons que l'on souhaite étudier les résultats d'un groupe d'étudiants. Pour chaque étudiant on dispose des informations suivantes :
- Son prénom qui est une chaine de caractères.
- Son age, qui est une donnée de type
integeroudouble. - Son sexe, qui vaut
TRUEsi c'est un homme etFALSEsi c'est une femme et est donc unlogical. - Ses notes dans différentes matières, qui sont des nombres de type
double.
Voici un tableau qui contient nos différentes données :
| Prénom | Age | Sexe | Economie | Mathématiques |
|---|---|---|---|---|
| Pierre | 26 | TRUE | 16 | 14 |
| Paul | 25 | TRUE | 14 | 18 |
| Marie | 22 | FALSE | 17 | 15 |
| Anna | 23 | FALSE | 13 | 16 |
Il nous serait impossible de représenter ces données dans une matrice ou dans un vecteur. La seule façon que nous connaissons pour représenter ces données est la liste (que nous avons dans la première partie de ce cours). Les data frames sont simplement des listes, dans lesquelles chaque colonne du tableau de données est représentée par un vecteur. Avec quelques restrictions suplémentaires par rapport à une liste classique :
- Un data frame ne peut contenir que des vecteurs.
- Tous les vecteurs doivent être de même longeurs.
- Tous les élements du data frame doivent avoir des noms différents ce qu'une liste n'oblige pas.
Créer un data frame
Pour pouvoir créer notre premier tableau de données, il nous faut... des données ! Commençons donc par créer un vecteur par future colonne de notre data frame. Ici, nous allons créer un vecteur de prénoms, un pour les ages, un pour le sexe, et un pour la note obtenue dans chaque matiére.
prenoms = c("Pierre", "Paul", "Marie", "Anna")
ages = c(26, 25, 22, 23)
sexes = c(TRUE, TRUE, FALSE, FALSE)
notes_economie = c(16, 14, 17, 13)
notes_mathematiques = c(14, 18, 15, 16)
Maintenons que nous avons notre matière premiére, construisons notre premier tableau de données. Pour cela il suffit d'utiliser la fonction data.frame() et de lui spécifier en paramétres le nom de chaque colonne ainsi le vecteur contenant les données de chaque colonne. Voici une illustration générique de l'utilisation de cette fonction :
data = data.frame(nom_colonne1 = vecteur1,
nom_colonne2 = vecteur2,
nom_colonne3 = vecteur3)
Utilisons cette nouvelle fonction data.frame pour créer un tableau de données contenant les informations sur chacun de nos étudiants :
data = data.frame(prenom = prenoms,
age = ages,
sexe = sexes,
note_economie = notes_economie,
note_mathematiques = notes_mathematiques,
stringsAsFactors = FALSE)
Et voici le résultat de notre data frame affiché dans la console :

Chaque vecteur à bien été associé à la colonne correspondante. On peut aussi remarquer que R nous propose automatiquement de numéroter sur la gauche les lignes de notre tableau de données. C'est plutôt pratique pour s'y repérer et celui permet d'identifier chaque ligne de façon unique.
Remarque : Nous avons introduit ici un nouveau paramétre à la fonction data.frame , le paramètre stringsAsFactors . Il permet d'indiquer si les chaines de caractères doivent être converties en facteurs automatiquement ou non. Par défaut, data.frame réalise toujours cette conversion car la valeur par défaut de stringsAsFactors est TRUE. Pour l'éviter, il faut donc passer sa valeur à FALSE comme ici.
Seconde syntaxe pour créer un data frame
Il existe une seconde syntaxe pour créer un tableau de donnée. Il est possible de spécifier les noms de chaque colonne uniquement à la fin, en utilisant un vecteurs de noms et le paramétre col.names , comme ceci :
data = data.frame(prenoms, ages, sexes, notes_economie, note_mathematiques,
col.names = c("prenom", "age", "sexe", "note_economie", "note_mathematique"),
stringsAsFactors = FALSE)
Si vous oubliez de spécifier le paramétre col.names , alors le data frame crée portera comme noms de colonnes les noms des vecteurs utilisés pour chaque colonne. Ici la première colonne se nommerai "prenoms", la seconde "ages", etc. Si vos vecteurs ont directement des noms qui correspondent aux noms de colonnes, pouvez ainsi créer rapidement votre tableau de données en écrivant uniquement la liste des vecteurs :
data = data.frame(prenoms, ages, sexes, notes_economie, notes_mathematiques)
On obtient le même tableau de données, simplement avec des noms de colonnes différents et peut-être un peu moins clairs :
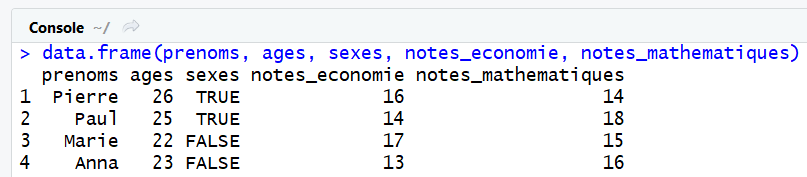
Cette méthode et la première syntaxe vue au dessus donnent le même résultat, c'est à vous de voir la syntaxe qui a votre préférence. Personnellement, nous préferons utiliser la première, qui à l'avantage de faire correspondre explicitement le nom de chaque colonne au vecteur de données associé.
Remarque : Si vous créer directement un vecteur qui n'a pas de nom, par exemple avec la syntaxe 1:n et que vous nommez pas les colonnes non plus, alors R va générer automatiquement un nom de colonne pour vous. Voici une illustration :
tableau_donnees = data.frame(prenoms, ages, 1:4) #la 3éme colonne n'est pas nommée
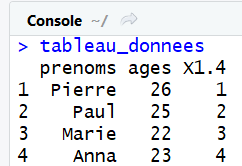
La troisième colonne, sans nom, à été automatiquement nommée X1.4 par R. Néanmoins, nous conseillons de toujours donner un nom à vos colonnes et de ne jamais laisser R le faire tout seul. En effet, cela peut parfois produire des noms à ralonge très particuliers. Aussi, si vous trouvez un nom de colonne étrange, il est probable que vous ayez simplement oublié d'en spécifier un.
Vérifions le type et la classe
Comme à notre habitude dans ce cours, vérifions le type de donnée et la classe de notre nouvelle structure. Les dataframes étant des listes avec des restrictions suplémentaires, nous nous attendons donc à y retrouver le type list qui indique la nature des données :
typeof(data) #affiche "List"
C'est bien le cas.
La classe de notre objet data quant a elle est data.frame , et correspond à la structure de données qui est représentée. Là aussi, nous obtenons le résultat attendu.
class(data) #affiche "data.frame"
Manipuler notre data frame
Nous allons voir maintenant comment manipuler et modifier notre data frame. Nous n'aborderons ici que quelques notions de bases : la partie cinq de ce cours sera consacrée de façon plus détaillée à ce sujet.
Modifier les noms de lignes et de colonnes
Modifier les noms de lignes
Par défaut, R propose de numéroter les lignes de notre data frame. Mais nous pouvons également nommer les lignes tout comme on peut nommer les éléments d'un vecteur. Pour cela, il suffit d'utiliser la fonction row.names() que nous avons déjà rencontré au chapitre précédent pour les matrices.
Donnons les prénoms de chaque étudiant comme noms de lignes de notre tableau de données :
row.names(data) = prenoms #le vecteur "prenoms" a été déclaré plus haut
print(data)

Il est néanmoins assez rare que l'on nomme les lignes d'une table de donnée. En effet, les noms doivent être uniques. Dans le cadre d'étudiants, il est par exemple possible que deux étudiants aient le même prénom. Il est donc préférable de laisser R numéroter les lignes, et de stocker les informations propres à chaque élément de notre tableau dans les colonnes.
Modifier les noms des colonnes
Il est plus utile de pouvoir modifier le nom des colonnes de notre data frame. La première option consiste à renommer l'ensemble des colonnes, avec la fonction names() . Elle fonctionne de la même façon que son homologue row.names() , à savoir qu'il suffit de lui associer un vecteur de noms.
names(data) = c("colonne1", "colonne2", "colonne3", "colonne4", "colonne5")
En général, on souhaite modifier seulement une seule colonne. Pour cela, il suffit de selectionner la colonne en question, puis d'en modifier le nom. Par exemple pour modifier la premiére colonne :
names(data)[1] = "prenom_eleves"
On peut de même selectionner plusieurs colonnes. Par exemple pour renommer les colonnes 1 et 4 :
names(data)[c(1, 4)] = c("col1", "col4")
Il existe des packages en R qui permettent de faciliter la selection et le renommage des colonnes. En attendant la partie cinq de ce cours, ces méthodes de base devraient nous suffir.
Selectionner des lignes, colonnes, ou éléments dans notre tableau de données
Les data frames étant des listes, on peut utiliser les mêmes méthodes que nous avons vu dans le chapitre sur les listes pour selectionner des éléments.
Selectionner une colonne
Pour selectionner une colonne dans un data frame il suffit d'indiquer entre doubles crochets le numéro de la colonne en question.
col1 = data[[1]] #on selectionne le contenu de la premiére colonne
class(col1) # "character"

Le résultat obtenu est alors le vecteur de la colonne en question.
Selectionner plusieurs colonnes
La syntaxe a doubles crochets permet d'extraire uniquement une seule et unique colonne, sous forme de vecteur.
Selectionner plusieurs colonnes revient à "réduire" le data frame originel, et à n'en garder que les colonnes qui nous intéressent. Pour cela, il faut utiliser la syntaxe avec double acollades et préciser les différente colonnes que l'on souhaite.
cols = data[c(1, 3)] #on selectionne les colonnes 1 et 3 et on récupere un dataframe
class(cols) # "data.frame"

Selectionner un ou plusieurs lignes
On peut selectionner des lignes en utilisant la syntaxe à simples crochets. Il est alors nécessaire d'indiquer en premiére coordonnées l'ensemble des lignes à selectionner, et de laisser la seconde coordonnée vide pour selectionner toute les colonnes.
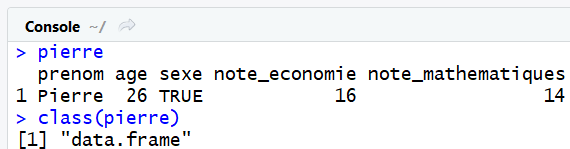
Selectionner ici le premier étudiant du tableau :
pierre = data[1,] #on selectionne la premiére ligne du tableau de données
class(pierre)
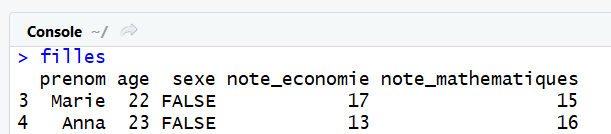
Il est bien entendu possible de selectionner plusieurs lignes avec un vecteur en premiéres coordonnées :
filles = data[c(3, 4), ] #on selectionne uniquement les filles
Selectionner à la fois dans les lignes et les colonnes
Il est possible de combiner les deux syntaxes de selection de lignes et de colonnes pour faire une selection précise. Il suffit d'indiquer le vecteur des lignes en premiére coordonnée, et le vecteur des colonnes en secondes coordonnées. Bien entendu, il faut là encore faire appel à la syntaxe à simple crochet.
Selectionnons par exemple uniquement les prenom, age et notes d'économie des garçons :
data[c(1, 2), c(1, 2, 4)]
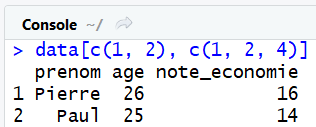
Il est aussi possible de selectionner un seul élement. Par exemple pour obtenir uniquement l'âge de Marie, nous pouvons procéder ainsi, sachant que Marie correspond à la 3éme ligne et que l'âge est la seconde colonne du tableau de données :
ageMarie = data[3, 2]
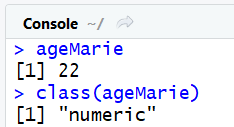
Nous pouvons remarquer que bien que nous utilisons la syntax à simple crochet, l'élement récupéré est bien un objet de type nombre et non un data frame.
Selection avancée :
L'ensemble des méthodes de selection que nous avons vu au chapitre sur les vecteurs fonctionnent également pour selectionner ou non certaines lignes et colonnes dans un tableau de données. Ainsi vous pouvez :
Utiliser un indice négatif pour indiquer les lignes ou colonnes à ne pas selectionner et garder toutes les autres. Par exemple pour selectionner tous les étudiants sauf Paul :
data[-2, ].
Utiliser un vecteur de booléen pour selectionner des lignes ou colonnes avec
TRUEet ne pas les selectionner avecFALSE.Selectionner les colonnes via leurs noms. Ainsi selectionnons la colonne âge :
data[, "age"]. Vous pouvez aussi utiliser la syntaxedata$agepour selectionner la colonne age.
Ajouter ou retirer des lignes et des colonnes
Maintenant que nous savons selectionner des élements dans notre tableau de données, regardons comment ajouter ou retirer des lignes ou des colonnes.
Ajouter une ligne
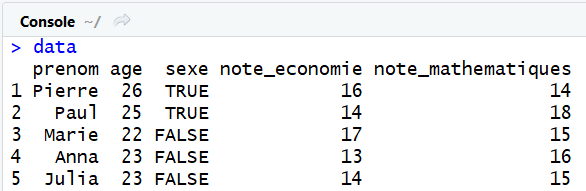
Supposons que l'on souhaite ajouter une nouvelle étudiante à notre base de données : Julia. Voici ses caractéristiques, qui sont stockées dans une liste :
julia = list("Julia", 23, FALSE, 14, 15)
Pour l'ajouter à notre tableau de données existant, il nous faut utiliser la fonction rbind() que nous avons déjà vu au chapitre sur les matrices. Cette fonction permet de fusionner deux élements par les lignes (d'où le nom rbind comme abréviation de row bind, soit fusion par les lignes).
data = rbind(data, julia)
Ajouter plusieurs lignes
Pour ajouter plusieurs lignes, deux solutions sont possibles. La première consiste à les ajouter manuellement les unes à la suite des autres avec rbind . Cela peut être un peu fastidieux. Une autre solution plus pratique revient à regrouper les nouvelles lignes dans un second tableau de données, et de fusionner les deux tableaux par le bas avec la même fonction rbind .
data = rbind(data, data_frame2)
Ajouter une colonne
Ajouter une colonne à notre tableau de donnée est une opération souvent utile. Pour cela, on peut utiliser la syntaxe data$nouvelle_colonne = vecteur . Essayons d'ajouter une nouvelle note pour chaque étudiant de notre tableau :
notes_philo = c(15, 12, 14, 14, 13)
data$note_philosophie = notes_philo
Et voilà notre nouvelle colonne ajoutée !

Ajouter plusieurs colonnes
Si vous voulez ajouter plusieurs colonnes en même temps, vous devez utiliser la fonction "jumelle" de rbind , à savoir cbind . Nous l'avions également croisée lors du chapitre sur les matrices. Comme vous vous en doutez, elle combine les élements entre eux par les colonnes.
Voici comment simplement ajouter deux nouvelles colonne a notre tableau de données :
notes_anglais = c(8, 14, 16, 15, 13)
notes_programmation = c(17, 13, 8, 12, 12)
data = cbind(data, colonne1, colonne2)
Et voilà notre data frame avec deux matières de plus : Comme vous pouvez le voir, les noms des nouvelles colonnes correspondent aux noms des vecteurs utilisés. N'oubliez pas que vous pouvez les changer à l'aide des méthdes que nous avons vu plus haut.
Comme vous pouvez le voir, les noms des nouvelles colonnes correspondent aux noms des vecteurs utilisés. N'oubliez pas que vous pouvez les changer à l'aide des méthdes que nous avons vu plus haut.
Retirer un ou plusieurs lignes
Pour retirer des lignes, il suffit de re définir la variable qui contient notre data frame en excluant les lignes que l'on ne souhaite pas garder. Par exemple, supprimons Pierre et Paul de notre tableau de données, en sachant qu'ils occupent respectivement les lignes 1 et 2 :
data = data[c(-1, -2),]

Retirer une ou plusieurs colonnes
La même méthode fonctionne pour retirer des colonnes, mais cette fois en spécifiant les colonnes à retirer. Essayons de retirer la colonne sexe de notre tableau de données :
data = data[, -2]
On reprend ici notre tableau tel que nous l'avons laissé à l'étape précédente, c'est à dire en ayant retiré Pierre et Paul. Et voici le résultat : 
Conclusion :
Nous avons vu dans ce chapitre l'une des principale structure de données utilisée en R : le data frame, ou tableau de données. Nous avons également vu rapidement les principales manipulations possibles qui sont réalisables avec. Lors du chapitre consacré à la manipulation des données, nous présenterons plus en détails de nouvelles façons pour travailler encore plus efficacement avec les tableaux de données.
A retenir :
- Les data frames ou tableau de données sont des listes de vecteurs de noms différents et de même longeurs. Ils permettent de représenter des bases de données qui regroupe des éléments de différente nature. Ils ont ainsi la classe
data.frameet le typelist. - On créer un tableau de données avec la fonction
data.frame()et en lui passant en paramétres les vecteurs qui correspondent à chaque colonne selon la syntaxedata.frame(nomColonne = vecteur1, nomColonne2 = vecteur2). - Il existe un paramètre optionnel et très utile qui est
stringsAsVectorsqui est par défaut àTRUE. Il faut le desactiver si on ne veut pas les chaines de caractéres soient automatiquement converties en vecteurs. - On peut selectionner des élements dans un data frame avec les mêmes méthodes que pour les listes. En particulier, la syntaxe à double crochets
[[]]permet d'extraire un vecteur, alors que la syntaxe a simples crochets permet d'extraire un sous data frame. - Il est possible d'ajouter ou de retirer des lignes des data frames, en particulier avec les fonctions
cbind()etrbind()que nous avons vu au chapitre sur les matrices.