Mettre en ordre les données
Maintenant que nous avons importé nos données sous forme de tibble , nous allons devoir passer par une étape importante : ordonner les données correctement, ou les "tidyfier". En anglais, "tidy" signifie "bien rangé", "ordonné", et c'est de là que vient le nom du tidyverse . Il s'agit d'un ensemble de packages qui permettent de ranger les données correctement et de travailler avec des données.
Dans ce chapitre, nous allons voir ce que signifie "bien ranger" les données, et nous allons voir comment le package tydr peut nous aider à cela.
La philosophie tidy
Organiser correctement ses données permet par la suite de travailler avec de façon plus efficace. Reprenons notre tableau de données des chapitres précédents, et regardons comment il est organisé :
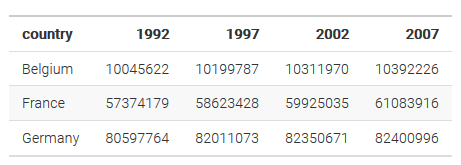
On peut voir que chaque ligne représente l'ensemble des observations de la population pour un pays. Ce tableau est facile à lire pour nous humains et nous semble bien ordonné non ? Pourquoi voudrions nous ordonner les données de façon différente ?
Contrairement à ce qu'on pourrait croire, ce tableau est en réalité mal ordonné. Il est facile à lire pour l'observateur, mais il est compliqué de travailler avec pour l'ordinateur. Nous allons comprendre plus facilement ce qui pose problème en découvrant les régles de l'organisation des données.
L'idée de données bien organisées (tidy data) à été proposée par le chercheur Hadley Wickham dans cet article. Depuis, cette idée à été adoptée par la majorité des particiens de l'analyse de données. repose sur un certain nombre de régles simples, qui rendent ensuite les données bien plus facile à manipuler. Voici ces régles :
- Régle 1 : Chaque ligne d'un data frame doit correspondre à une observation. Ici, on voit bien que cette régle n'est pas respectée, car chaque ligne correspond à l'ensemble des observations pour un pays.
- Régle 2 : Chaque colonne doit correspondre à une variable. Ici, ce n'est pas le cas : 1997 par exemple ne correspond pas à une variable, mais à la réalisation d'une variable (la population) pour une année donnée. A l'inverse, la variable population (qui est ce qu'on étudie dans ce tableau) n'apparait pas !
Voici comment nous pourrions transformer notre tableau de données pour le rendre "tidy" :
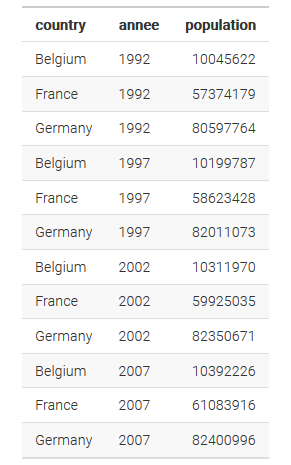
On voit que avec cette nouvelle organisation, on a bien une observation par ligne, et une variable qui est représentée par une colonne à chaque fois.
Cette présentation peut sembler plus compliquée à lire pour nous humains, mais elle est en réalité beaucoup plus pratique. Elle nous permettra par exemple de réaliser facilement des régressions linéaires, des analyses de séries temporelles, ou encore des représentations graphiques. En effet, toutes les fonctions du tydiverse attendent des tableaux de données ordonnées sous ce format là. Il est donc essentiel de bien le respecter et de ranger nos données correctement.
Le package Tydr
Pour nous aider à rendre nos données organisées, le tydivsere nous fourni le package bie nommé tydr . Nous allons en découvrir les principales fonctions et voir comment elles peuvent nous aider. Comme d'habitude, installons et chargeons le package, si ce n'est pas déjà fait :
install.packages("tidyr")
library("tidyr")
Les fonctions gather() et spread()
Le package comporte deux fonctions principales, qui font chacune l'inverse de ce que fait l'autre. La fonction gather() permet de "tidyfier" nos données, alors que la fonction spread() permet de réaliser l'opération opposée. Voyons en pratique comment utiliser ces deux fonctions.
Tidyfier les données avec gather()
Partons de notre data frame data , au format non rangé :
library("tidyverse")
data = read_csv("data.csv")
View(data)
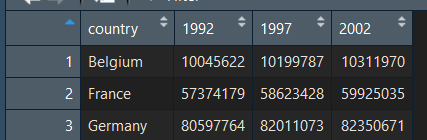
Comme aimerions pouvoir ordonner ce tableau de données, pour qu'il respect les régles de données "tidy". La fonction gather() réalise ce travail pour nous :
data_tidy = gather(data, key = "annee", value = "population", -country)
Et voici le résultat :
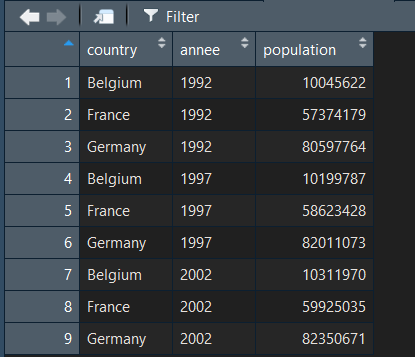
La fonction gather() prend un tableau de données, et considére que toutes les colonnes doivent être transformée en une variable catégorielle ou "etiquette" et une variable de valeur. Ici, l'idée est de transformer les colonnes 1992 , 1997 et 2002 en une colonne année et une colonne population . Tout en gardant la colonne country qui elle n'a pas besoin d'être modifiée.
Examinons en détail les différents arguments de la fonction gather() :
- Le premier argument est le tableau de données que l'on souhaite tidyfier.
- Le second argument
keyindique le nom de la colonne qui va être créer pour servir d'étiquête et indiquer l'année de l'observation. - l'argument
valueindique le nom de la colonne qui contiendra les valeurs associées à chaque observation de la clef. Ici, l'observation liée à chaque année est bien la population du pays. - Enfin, en dernier argument sans nom on ajoute les noms des colonnes qui ne doivent pas être prisent en compte avec un
-devant. On peut passer soit un vecteur de noms de colonnes, soit un vecteurs de nombres avec les numéros de colonnes en négatif, icic(-1)au lieu de-country.
Il est également possible de passer en dernier argument uniquement les colonnes que l'on souhaite transformer :
data_tidy = gather(data, key = "annee", value = "population", "1992":"2002")
Ici en écrivant "1992":"2002" on spécie à R que l'on souhaite transformer toutes les colonnes comprises entre la colonne 1992 et la colonne 2002 .
Selon l'organisation de votre tableau de donnée, il est parfois plus pratique soit de spécifier les colonnes à transformer, soit de spécifier les colonnes à exclure comme vu plus haut.
Dans les deux cas, si on oublie de dire à gather() de ne pas prendre en compte certaines colonnes, alors toutes les colonnes vont être transformée en catégorie, et voici ce qu'on obtient :
data_tidy = gather(data, key = "annee", value = "population")
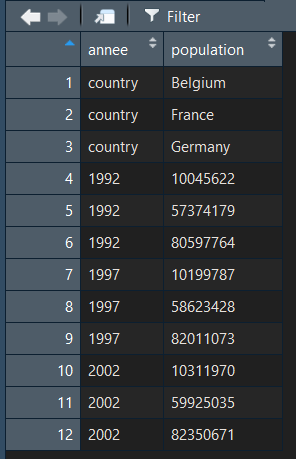
On voit que dans ce cas, R à pris en compte la colonne country, et a associé une clef (country) avec les différentes valeurs (Belgium , France et Germany . Ce qui n'est pas du tout ce que nous voulions faire. Il est donc important de bien préciser les variables que l'on souhaite exclure si certaines colonnes sont directement bien formatée.
spread()
La fonction spread() permet de faire l'opération inverse de celle réalisée par gather() . Cette fonction est moins utilisée, mais cela est parfois pratique. Voyons comment elle fonctionne et essayons de faire revenir notre tableau data_tidy à son état initial avant transformation.
data_originel = spread(data_tidy, key = "annee", value = "population")
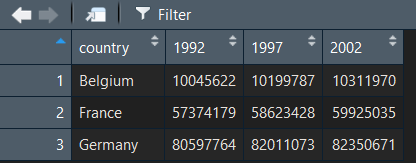
Et on retrouve exactement notre tableau de données de départ ! La fonction spread() fonctionne de façon parfaitement symétrique à la fonction gather() . Il suffit de lui indiquer la colonne qui contient les noms des variables en key et celle qui contient leurs valeurs en value et elle fera le travail en sens inverse.
unite() et separate()
Il existe deux autres fonctions dans le package tidyr : les fonctions unite() et separate() . Les deux sont là aussi l'inverse l'une de l'autre. La première permet de "fusionner" les données de plusieurs colonnes en une seule. Par exemple si un data frame contient une colonne heure et une colonne minutes on peut vouloir les fusionner les deux au format hh-mm . La fonction unit() nous permet de faire cela. La fonction separate() permet de faire l'opération inverse, en séparer une colonne selon un motif donné en différentes colonnes.
Si vous voulez en savoir plus sur ces deux fonctions, n'hésitez pas à aller consulter la documention. En pratique, elles ne servent que très rarement, c'est quoi nous nous contentons de mentionner leur existance.
A retenir :
- Les données bien rangées ("tidy data") se caractérisent par une observation par ligne et une variable par colonne. Ainsi que par une occurence unique de chaque observation par table.
- Il est important de travailler avec des données bien ordonnées, car la plupart des fonctions de R et du tidyverse ne fonctionnent qu'avec des données à ce format.
- Le package
tydrdutidyversepropose la fonctiongather()pour "tidyfier" les données, ainsi que son complémentspread().