Transformer les données
Nous avons vu au chapitre précédent comment "tidyfier" nos données, pour les organiser correctement. Nous allons voir ici comment transformer nos données : ajouter ou supprimer des variables, en modifier, fusionner des data frames, etc. Pour cela, nous allons utiliser le package dplyr qui fait parti du tidyverse .
library("dplyr") #on charge le package si cela n'a pas déjà été fait !
Les différentes opérations possibles
Reprennons notre jeux de données d'exemple :
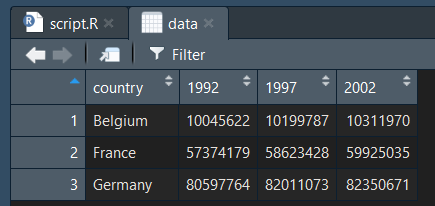
Voyons quelles opérations de base nous pourrions vouloir faire subir a un tableau de données :
- Renommer une colonne : Donner un nouveau nom à une colonne que celui d’origine.
- Sélectionner certaines colonnes : Il est possible que notre jeux de données comprenne des colonnes qui ne nous intéressent pas, ou que l’on souhaite conduire une analyse en utilisant uniquement certaines variables. Il peut être alors utile de ne sélectionner que certaines colonnes.
- Ajouter une colonne : On peut vouloir ajouter de nouvelles colonnes, calculées par à partir des colonnes existantes. Par exemple ajouter une colonne qui indique la variation de la population entre 1992 et 2002.
- Filtrer les données : On peut ne vouloir travailler que sur certaines données. Par exemple on peut essayer de travailler uniquement les pays qui ont plus d'un certain nombre d'habitants.
- Classer les données : Classer une colonne par ordre alphabétique ou par ordre croissant. Cela permet par exemple de classer directement les pays par ordre croissance de population.
- Fusionner deux jeux de données : On dispose par exemple d’un nouveau jeux de données qui apporte des données sur l’éducation des filles dans chaque pays et on souhaite l’ajouter à notre jeux de données existant.
Pour chacune de ses opérations, le package dplyr va nous fournir une fonction très pratique et très rapide pour manipuler les données et obtenir le résultat souhaiter.
la fonction Select()
La première fonction que nous allons voir est la fonction select() . Comme son nom l'indique, elle nous permet de selectionner des colonnes.
#On selectionne les populations en 2002
data2 = select(data, c("contry", "2002"))
View(data2)

La fonction select() est assez simple : elle prend en premier paramétre le data frame dont on veut selectionner des colonnes, et ensuite les colonnes qui nous intéressent.
Il est possible d'utiliser ce qu'on sait sur les vecteurs pour des selections plus avancées :
data = select(data, c(-3)) #On peut aussi exclure des colonnes en numéros
data = select(data, 1:3) #On peut selectionner une plage avec les numéros de colonnes
data = data2 = select(data, country:`1997`) #cela marche aussi avec les noms
# les ` permettent d'éviter que 1997 soit interprété comme un nombre.
La fonction Mutate()
La fonction mutate() permet de créer une nouvelle variable à partir de celles existantes. Essayons de créer une nouvelle colonne difference qui indique la variation de la population entre 2002 et 1992 .
data2 = mutate(data, difference = `2002` - `1992`)

Et voilà une nouvelle colonne est apparue !
La syntaxe de la fonction mutate() est simple : le premier argument est le tableau de données d'orgine, et le second argument est le nouvelle de la nouvelle variable avec son mode de calcul. Ici comme les colonnes ont des noms qui sont des chiffres, on doit les entourer de ````` pour que R sache qu'il s'agit de noms de colonnes et non de chiffres.
La fonction Rename()
Comme son nom l'indique, la fonction rename() permet de renommer les variables d'un data frame. Ici nous allons nous en servir pour renommer les noms des colonnes 1992 , 1997 et 2002 pour qu'ils ne soient plus des nombres.
data = rename(data, "pop_1992" = `1992`, "pop_1997" = `1997`, "pop_2002" = `2002`)
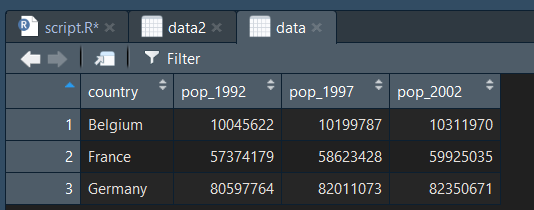
Comme vous vous en doutez, cette fonction sert assez souvent ! Heureusement, elle est facile d'utilisation comme on vient de le voir.
La fonction Filter()
La fonction filter() permet de filter nos données pour en selectionner une partie seulement. C'est là aussi une fonction très utile. Ici, on cherche à selectionner les pays dont la population en 2002 est supérieure à 70 millions d'habitants.
data2 = filter(data, pop_2002 > 70000000)

Comme prévu, seule l'Allemagne dispose d'une population supérieure à 70 millions d'habitants en 2002. Le fonctionnement de base de filter() est simple : il suffit d'indiquer le nom du data frame en premier argument, et la condition du filtre en second argument.
On peut aussi filtrer par égalité. Si on transforme notre data set pour le rendre "tidyfié" et qu'on filtre pour avoir les données de la France :
data_tidy = gather(data, key = "annee", value = "population", -country)
data_tidy = filter(data_tidy, country == "France")

Filtres multiples
On peut combiner différents filtres sur différentes variables :
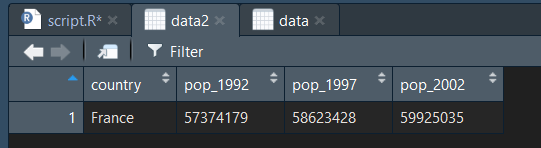
data2 = filter(data, pop_2002 > 20000000, pop_2002 < 70000000)
On filtre ici les pays dont la population en 2002 est supérieure à 20 millions mais inférieure à 70 millions :

Comme attendu, seule la France est dans ce cas là.
Filtre avec les opérateurs logiques
On peut aussi filtrer avec des opérateurs logiques | ou & pour combiner les différents filtres. Le filtre précédent écrit avec un signe & :
data2 = filter(data, pop_2002 > 20000000 & pop_2002 < 70000000)
Vous pouvez utiliser le signe | pour filtrer selon l'une ou l'autre des conditions, et le signe & pour filtrer selon les deux conditions (dans ce cas là, le filtre fonctionne comme si vous aviez séparé les filtres par une virgule comme vu précédement).
La fonction Arrange()
La fonction arrange() permet de trier le tableau de données. Par défaut, les données numériques sont triées par ordre croissant, et les chaines de caractéres sont classées par ordre alphabétique. On peut inverser l'ordre via les paramétre de la fonction.
data2 = arrange(data, country) #on trie par ordre alphabétique des pays
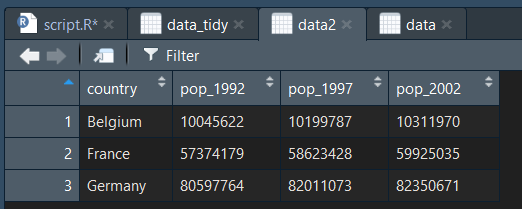
On peut trier par ordre descendant avec le paramétre desc :
data2 = arrange(data, desc(pop_2002)) #on trie par ordre décroissance selon la population
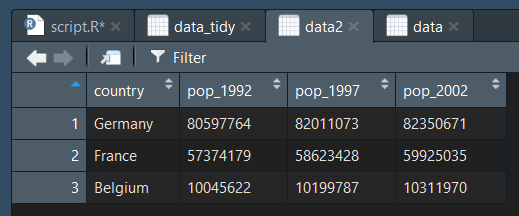
Attention, il faut bien entourer le paramétre de tri par desc() pour inverser l'ordre de tri !
Remarque : Vous pouvez spécifier d'autres variables, qui servirons à trier les valeurs en cas d'égalité sur la première variable :
data2 = arrange(data, variable1, variable2)
Fusionner des data frames avec left_join()
Il arrive souvent que l'on dispose de deux data frames qui contiennent chacun une partie des données, et que l'on souhaite les réunir. Par exemple imaginons ici que l'on dispose d'un data set qui contient les observation des années 1992 et 1997, et d'un qui contient celle de l'année 2002.
Construisons ces tableaux à l'aide de la fonction select() et des données originels :
data2 = select(data, c(1, 2, 3))
data3 = select(data, c(1, 4))
On dispose de deux tableaux de données que l'on aimerai réunir en un seul :
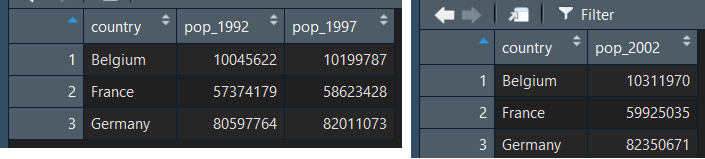
Pour les fusionner, nous pouvons utiliser la fonction left_join() qui nous permet de fusionner les tableaux de données par une variable commune. En effet, il s'agit ici d'ajouter des colonnes à chaque pays, la colonne country est commune aux deux data frame. Cette variable commune est indispensable pour la fusion.
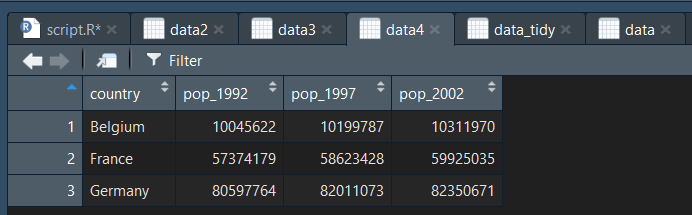
data4 = left_join(data2, data3, by = "country")
La fontion left_join() prend en premiers paramétre les noms des data frames à fusionner, et en paramétre by le nom de la variable commune. On a alors réussit à réunir nos données :
View(data4)
Remarque : Si il n’y a pas de variable commune ou qu’elle n’est pas exprimée dans la même unité on peut avoir intêret à transformer cette variable dans un des deux dataset pour les rendre compatibles.
A retenir
- Le package
dplyrfourni de nombreuses fonctions utilitaires pour transformer les données. Vous serez souvent ammenés à utiliser ces fonctions au cours de votre utilisation de R. select()permet de selectionner des colonnes de différentes façons.mutate()permet de créer de nouvelles variables à partir de celles existantes.rename()permet de renommer les colonnes de nos tableaux de données.filter()permet de filtrer uniquement les observations qui répondent à certains critéres.arrange()permet de trier les données par ordre alphabétique/croissant. On peut trier par ordre décroissant en entourant la variable de tri dedesc().left_join()permet de fusionner entre eux deux data frames qui possédent une variable commune.